被业界公认为人脸识别“世界杯”的微软百万名人识别竞赛 MS-Celeb-1M 2017结果近日公布。由重庆研究院和中科院自动化研究所组建的合作团队(CIGIT-NLPR),在所有子竞赛中获得亚军。
MS-Celeb-1M的竞赛任务是准确识别百万人脸,是业界公认的人脸识别年度“世界杯”,目前世界上规模最大、水平最高的图像识别赛事之一。由微软技术与研究院(Microsoft Technology and Research)发起,借助计算机视觉顶级会议定期举办,每年均有来自全世界的多支顶级团队参赛,竞赛非常激烈。此次合作团队参加了其中三项子竞赛(Hard Set/Random Set/Low-Shot Learning)的比拼。
此次的竞赛项目中,除了以往设置的识别百万名人子命题(Recognizing One Million Celebrities)用于检验各参赛队大规模的人脸识别算法性能,赛事组织者还增设了识别单一训练样本名人(Low-Shot Learning)的新命题,重点考察小样本的学习能力。识别百万名人子命题组织方给出了10万名人的训练数据,1000万弱标注(不保证每张图像对应的人名正确)的图像和100万人的名单。评测数据是从100万人中选取5万张图片,分为随机挑选数据(Random Set)和困难数据(Hard Set)两个评测数据集,有25%的数据在10万名人的训练名单中。(团队成员:CIGIT-刘鹏程、程诚、邵枭虎、冯友计、徐卉、杨雪琴、周祥东、石宇 / NLPR-兴军亮、李凯)
识别单一训练样本名人项目,赛事组织方共提供两个数据集:Base Set和Novel Set。其中,Base Set共包含2万个名人,每个名人仅有50~100张图片用于训练;Novel Set包含1000个名人,每个人只有 1~5张用于训练。在测试集上,参赛队伍需要在保证Base Set中名人识别率在99%的前提下,最大限度地识别出Novel Set中的1000个名人。(团队成员:CIGIT-冯友计、程诚、刘鹏程、邵枭虎、徐卉、杨雪琴、周祥东、石宇/ NLPR-兴军亮、李凯)
经过数天的激烈角逐,我们团队搭建的人脸识别系统在Random Set/Hard Set上的评测均获得亚军,识别性能较去年也有大幅度的提高,充分体现了团队算法和技术在大规模人脸识别的国际领先水平。在Low-shot Learning竞赛取得的佳绩也充分证明了我们团队能够有效解决稀缺人脸训练样本的识别难题。
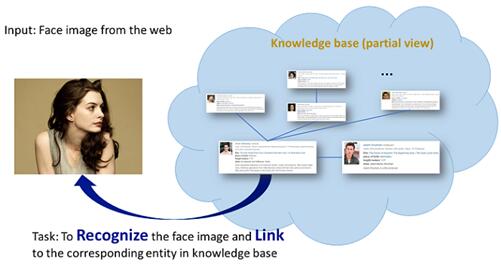
识别百万名人子命题
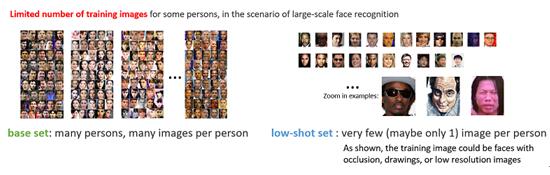
识别单一训练样本名人