

科研进展
重庆研究院在决策智能公平性与高质量数据生成及利用领域取得系列进展
时间:2025-11-27编辑:大数据与无人系统研究中心
决策智能作为人工智能赋能复杂系统的核心环节,旨在使机器能够自主感知、推理并执行最优策略,已成为推动无人系统、推荐平台与机器人智能化发展的关键引擎。然而,现有决策系统在迈向高阶自主的过程中,仍面临三大核心瓶颈:长期价值与短期收益的权衡困境,个体智能与群体协同的整合难题,以及模型效能与数据效率的固有矛盾,这些瓶颈不仅制约了系统的长期可靠性与协同效率,也阻碍了智能决策技术在资源受限场景中的落地应用。针对上述挑战,重庆研究院大数据与无人系统研究中心近期在决策智能领域取得系列突破,研究团队围绕长期可靠决策、多体协同决策与高质量数据蒸馏等提出了创新性的解决方案,三篇相关论文被人工智能国际会议AAAI 2026录用。
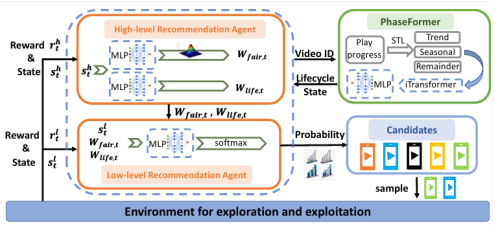
重构推荐公平性范式:以生命周期为核心的动态决策机制。交互式推荐系统(如短视频推荐)在提供个性化体验的同时,也面临长期公平性失衡的挑战:系统往往过度偏向热门内容,冷门或新内容难以获得曝光,形成“强者恒强”的马太效应。这种“流行度偏见”在长期运行中不断累积,最终破坏内容生态的多样性与可持续发展。针对这一问题,研究团队提出一种全新的视角——将数字内容的“生命周期”作为智能决策的控制变量。通过对海量短视频数据的系统分析,团队发现现代数字内容普遍遵循“快速成长—短暂稳定—迅速衰退”的三阶段新规律,这与传统的四阶段生命周期模型明显不同。基于这一发现,团队提出生命周期感知的分层强化学习框架(LHRL),实现了对推荐系统“短期用户满意度”与“长期生态公平性”的动态平衡。LHRL框架由两个核心部分组成:
*生命周期识别模块(PhaseFormer):利用时间序列分解与注意力机制,准确识别每个内容所处的生命周期阶段。
*分层决策机制:高层策略根据生命周期阶段设定长期公平性约束,低层策略在此指导下优化即时推荐效果,从而在两种目标之间实现自适应协调。
实验结果显示,该机制可在保持用户满意度的同时,将长期用户参与度提升超过10%,显著改善了内容分布公平性。该研究首次揭示了生命周期因素在推荐公平性调控中的关键作用,为构建可持续、公平、可信的推荐生态提供了新的决策范式。相关成果以“Revisiting Fairity-aware Interactive Recommendation: Item Lifecycle as a Control Knob”为题被AAAI 2026录用(论文作者:鲁云,史晓雨,谢洪,夏崇珺,龚政辉,尚明生)。
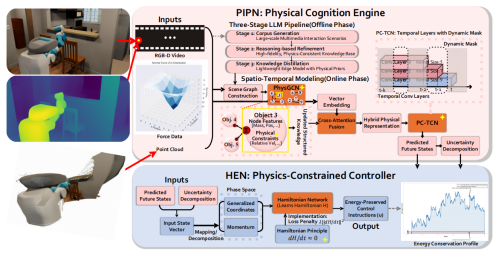
突破多机器人协同决策的通信瓶颈。在复杂物理环境中实现多机器人协同作业,是群体智能研究的重要方向。然而,当前系统长期受制于“通信与协同”的双重约束:集中式决策需要传输大量感知数据,造成通信延迟;而完全分布式决策又难以保证全局协调精度。这一通信-决策矛盾成为制约多机器人智能协作的关键瓶颈。为此,研究团队提出PIPHEN分布式物理认知与控制框架,通过从“数据通信”向“语义通信”转变,显著提升多机器人协同效率。该框架包含两大核心模块:
*物理交互预测网络:在机器人端侧进行“语义压缩”,将高维感知数据提炼为少量、物理含义清晰的语义特征,实现从感知到认知的转化。
*哈密顿能量网络:基于能量守恒原理,对语义特征进行物理约束控制,生成协调一致、物理可解释的动作指令。
通过构建“感知–认知–决策”闭环体系,PIPHEN有效实现了低通信量下的高精度协同控制。实验结果表明,该框架可将协同决策延迟从315毫秒显著降低至76毫秒,同时显著提升任务成功率和系统稳定性。该研究为无人系统在复杂动态场景中的高效、可靠、可解释协作提供了全新技术路径。相关成果以“PIPHEN: Physical Interaction Prediction with Hamiltonian Energy Networks”为题被AAAI 2026录用并作口头报告(论文作者:陈可为,龙垭宇,尚明生)。
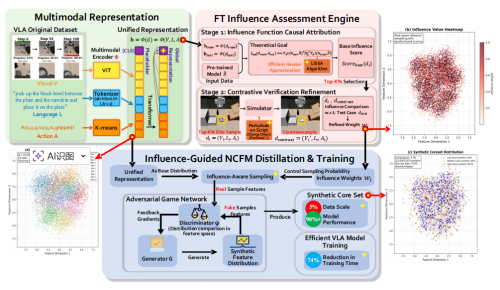
构建高效决策模型的数据精炼新路径。视觉-语言-动作(VLA)模型是支撑机器人理解世界与执行复杂任务的关键技术。然而,此类模型的训练高度依赖海量数据,带来巨大的计算与存储开销,使得高性能模型难以在资源受限的场景中部署。现有“以模型为中心”的优化方式(如模型压缩与蒸馏)虽能减轻部分负担,却未从数据层面根治效率瓶颈。针对这一挑战,研究团队提出FT-NCFM影响力感知数据蒸馏框架,开辟“以数据为中心”的高效模型训练新方向。其核心理念是:模型性能的关键不在数据量的多少,而在数据的质量与信息密度。FT-NCFM通过两大创新模块实现数据层优化:
*事实追踪引擎:量化每个训练样本对模型泛化能力的真实影响,识别高价值样本。
*影响力引导生成网络:基于高价值样本分布合成小规模但信息密集的“核心数据集”。
该框架使模型能够以更少的数据学习到更有效的知识。实验证明,仅使用5%的合成数据即可恢复原模型90%以上的性能,训练成本降低超过75%。该成果为在边缘设备上部署大规模智能模型提供了高效、经济且通用的数据优化范式。相关成果以“FT-NCFM: An Influence-Aware Data Distillation Framework for Efficient VLA Models” 为题被AAAI 2026录用(论文作者:陈可为,龙垭宇,李帅,尚明生)。
相关研究得到了国家自然科学基金、重庆市自然科学基金重点项目、重庆市技术创新与发展重大专项等资助。AAAI由国际先进人工智能协会主办,是人工智能领域全球最富盛名的学术会议之一,被中国计算机学会认定为A类国际学术会议。AAAI 2026将于2026年1月在新加坡举行。AAAI 2026共收到23,680篇论文投稿,录用率仅17.6%。
相关论文链接:
http://arxiv.org/abs/2511.16248
https://arxiv.org/abs/2511.16200
https://arxiv.org/abs/2511.16233
中国科学院重庆绿色智能技术研究院 版权所有京ICP备05002857号渝公网安备50010943035号

















